On this page
Guides
Extract Tables from PDFs
Overview
It is to extract tables from PDF documents.
Standard table and non-standard table
Commonly, tables can be divided into two categories: standard tables and non-standard tables. The specific definitions are as follows:
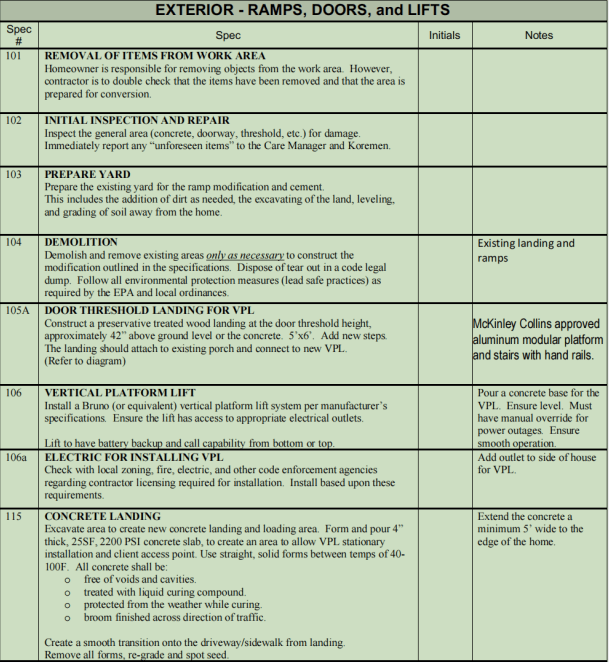
- Standard table: The table border and the inner lines of the table are complete and clear. There is no need to manually add table lines to divide the table content.
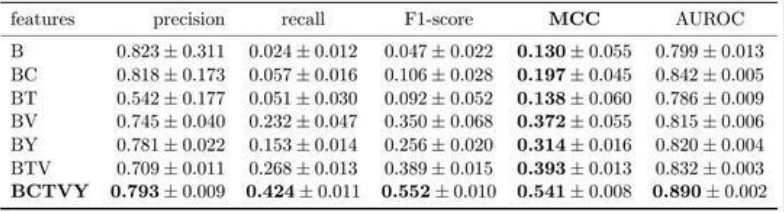
- Non-standard tables: Table borders or inner lines are missing, and table lines are unclear. Table lines need to be manually added to separate the table content.
Note
- Non-standard tables in the original PDF document cannot be extracted when the OCR option is not enabled.
- It is recommended to enable OCR or AI layout analysis options for higher accuracy of table extraction and the support of non-standard table recognition.
Sample
This is a sample to extract the table and table content from a PDF document.
c++
ConvertOptions opt;
// Extract PDF Table.
PDFToOffice::StartExtractPDFTable("text.pdf", "password", "path/output", opt, progress);