

In modern web development and design, converting the images of website designs directly into HTML+CSS code to quickly create web pages is highly demanded. Unlike traditional web design and development, image-to-HTML conversion, driven by AI, has become a possibility. Once the webpage is designed according to the idea of converting images to HTML CSS, the traditionally time-consuming and labor-intensive website development process is significantly shortened.
ComPDFKit offers well-trained artificial intelligence to power the image to HTML feature, making it easier to convert images into HTML code and thereby saving developers time and effort, enhancing their flexibility during the design and development stages. Integrate ComPDFKit image to HTML Conversion SDK or API (1000 free requests/month) into your apps now.
In the following article, we will explore how ComPDFKit leverages AI technology to achieve high-quality image to HTML code conversion.
Comparison of Popular Image to HTML Converters
We used certain design diagrams from ComPDF product materials as examples to test the popular Image to HTML converters available in the market. The sample images contain elements such as images, icons, text, titles, multi-column text, and dividers. Below are the performance results of each converter or technology provider.
- ComPDFKit: In the HTML result page, it is able to retain text, images, text boxes, image boxes, and design elements like lines and layouts from the original design. However, some font styles of the text and the sizes of images have slight discrepancies compared to the original design. Overall, compared to the other brands, ComPDFKit’s effect of converting images to HTML is the best.

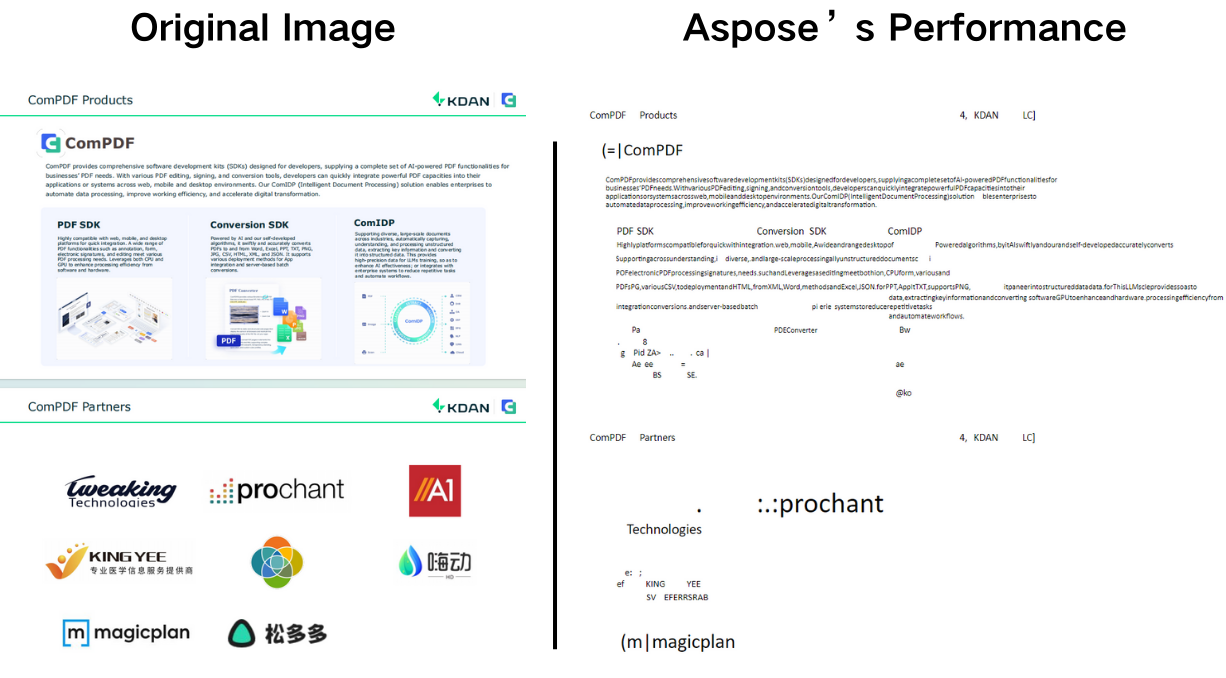
- Aspose: The result HTML file is a little disorganized, unable to perform layout analysis of the original image content, and fails to accurately identify icons and text. The positive aspect is that most of the text is recognized.
- Onetab: It is good at text extraction, with most HTML result pages maintaining a layout consistent with the original image. However, it does not perform well in recognizing and extracting designs and icons from the original image, with some discrepancies in the number of icons compared to the original.

- Fronty: This brand shows excellent accuracy in recognizing text and images, but there is still room for improvement in layout recovery, as some images from the original design are unnecessarily subjected to OCR.

- Fotor and Wordize: The converted HTML files from these two brands are entirely images within the HTML file. They cannot recognize the text and images and convert them into HTML and CSS.
Make API Requests in Java and Build Image to HTML Converters
The above text has already demonstrated the currently popular Image to HTML AI converters. The most effective one, ComPDFKit, enhances its various file conversion features with AI upgrades. Its extensively trained AI model library makes layout analysis, table recognition, text recognition, and unstructured data recognition more accurate, enabling it to better restore the content of the design image in the HTML result file.
If you wish to integrate ComPDF products, you can register for a ComPDFKit API account to get 1,000 free calls for one month. Follow the steps below to start integrating the ComPDFKit image-to-HTML API into your application!

Step 1: Authentication
To convert images to HTML, you need to replace the publicKey and secretKey fields in the following code which you can get from the console. Then, you can get the accessToken and verification-related information. AccessToken will expire after 12 hours. When calling the subsequent interface, you must carry this token in the request header: Authorization: Bearer {accessToken}.
import java.io.*;
import okhttp3.*;
public class main {
public static void main(String []args) throws IOException{
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("text/plain");
RequestBody body = RequestBody.create(mediaType, "{\n \"publicKey\": \"{{public_key}}\",\n \"secretKey\": \"{{secret_key}}\"\n}");
Request request = new Request.Builder()
.url("https://api-server.compdf.com/server/v1/oauth/token")
.method("POST", body)
.build();
Response response = client.newCall(request).execute();
}
}
Step 2: Create Task
You need to replace the accessToken which was obtained from the previous step, and choose the language type you want to display the error information (More image to HTML parameter details). After replacing them, you will get the taskId in the response data.
import java.io.*;
import okhttp3.*;
public class main {
public static void main(String []args) throws IOException{
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("text/plain");
RequestBody body = RequestBody.create(mediaType, "");
Request request = new Request.Builder()
.url("https://api-server.compdf.com/server/v1/task/img/html?language={{language}}")
.method("GET", body)
.addHeader("Authorization", "Bearer {{accessToken}}")
.build();
Response response = client.newCall(request).execute();
}
}
Step 3: Upload Files
Replace with the file you want to convert, image conversion supports uploading JPG, JPEG, PNG, and BMP, with the taskId obtained in the previous step, with the language type you want to display the error information, and with the accessToken obtained in the first step.
import java.io.*;
import okhttp3.*;
public class main {
public static void main(String []args) throws IOException{
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("text/plain");
RequestBody body = new MultipartBody.Builder().setType(MultipartBody.FORM)
.addFormDataPart("file","{{file}}",
RequestBody.create(MediaType.parse("application/octet-stream"),
new File("<file>")))
.addFormDataPart("taskId","{{taskId}}")
.addFormDataPart("language","{{language}}")
.addFormDataPart("password","")
.addFormDataPart("parameter","{ \"pageOptions\": \"1\" , \"isAllowOcr\": \"1\" , \"isContainOcrBg\": \"0\"}")
.build();
Request request = new Request.Builder()
.url("https://api-server.compdf.com/server/v1/file/upload")
.method("POST", body)
.addHeader("Authorization", "Bearer {{accessToken}}")
.build();
Response response = client.newCall(request).execute();
}
}
Step 4: Process Files
Replace with the taskId you obtained from the Create task step, and with the accessToken obtained in the first step, and replace with the language type you want to display the error information.
import java.io.*;
import okhttp3.*;
public class main {
public static void main(String []args) throws IOException{
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("text/plain");
RequestBody body = RequestBody.create(mediaType, "");
Request request = new Request.Builder()
.url("https://api-server.compdf.com/server/v1/execute/start?taskId={{taskId}}&language={{language}}")
.method("GET", body)
.addHeader("Authorization", "Bearer {{accessToken}}")
.build();
Response response = client.newCall(request).execute();
}
}
Step 5: Get Task Information
Replace the taskId and access_token which you get from previous steps. Request address: https://api-server.compdf.com/server/v1/task/taskInfo?taskId={taskId}&language=<language>
import java.io.*;
import okhttp3.*;
public class main {
public static void main(String []args) throws IOException{
OkHttpClient client = new OkHttpClient().newBuilder()
.build();
MediaType mediaType = MediaType.parse("text/plain");
RequestBody body = RequestBody.create(mediaType, "");
Request request = new Request.Builder()
.url("https://api-server.compdf.com/server/v1/task/taskInfo?taskId={{taskId}}")
.method("GET", body)
.addHeader("Authorization", "Bearer {{accessToken}}")
.build();
Response response = client.newCall(request).execute();
}
}Conclusion
Fully automated converting mage to HTML CSS remains challenging because the complexity and diversity involved go far beyond basic image processing and parsing.
However, with AI-powered image-to-HTML conversion, the portion of the initial HTML CSS code that requires manual adjustment has been significantly reduced. Now, use ComPDFKit image to HTML AI conversion features to greatly reduce web development time!