Since the debut of ChatGPT, developers have employed RAG (Retrieval-Augmented Generation) technology to integrate knowledge bases, enhancing Large Language Models (LLMs) without the need to retrain models for each specific task. This approach, combining LLMs' reasoning capabilities with external knowledge, markedly improves the accuracy of generated results. Therefore, to train high-quality AI models, knowledge bases must not only contain abundant data but also ensure data quality. In this situation, data providers play a crucial role.
However, due to the unstructured nature of PDF formats, their data cannot be directly used for AI training. Consequently, data providers invest significant labor to manually extract and process this unstructured data, which is time-consuming and error-prone.
To address this issue, a data provider turned to ComPDFKit for an efficient and dependable solution, aiming to leverage our data extraction capabilities to structure PDF documents. Tailoring a model based on their requirements and detection criteria using AI and various algorithms, we processed over 3 million PDF documents in just 5 days, delivering high-quality structured data. This not only alleviated their manual processing burden but also significantly boosted the efficiency and effectiveness of their clients' AI model training, thereby supporting them and their customers in expanding their business operations.

What Are Their Requirements
In the competitive Chinese data market, this provider boasts the largest repository of genuine, high-quality data. With AI technology rapidly advancing, an increasing number of clients turn to them for data to enhance their AI training. However, their client feedback suggests that manual-processed PDF data is insufficient in quality, leading to underwhelming AI model performance. Aware of ComPDFKit's reputation for fast, precise, and high-quality PDF data extraction services, they seek our assistance in extracting data from over 3 million PDF documents.
According to industry standards, ComPDFKit's data extraction ensures an accuracy rate of 80% per document, accurately identifying text, tables, images, headers, footers, etc., which meets the data detection standards of most enterprises. Yet, given the unique nature of AI model training, even a small 20% margin of dirty data within a document can significantly affect accuracy. Consequently, this provider has specified their requirements: segmented identification and orderly recording of multi-column or irregular layouts, along with the removal of elements like headers, footers, page numbers, and side-margin titles.
To meet these needs, ComPDFKit's dedicated R&D team has customized data extraction parameters precisely aligned with their data detection standards, ensuring that 80% of PDFs in over 3 million documents fully comply with their criteria.
What Technical Challenges We Overcome
Basic OCR functionality accurately extracts plain text from PDF documents. However, recognizing text in different formats, layouts, and fonts, as well as identifying images, charts, tables, and other content, poses key and challenging aspects for improving data extraction accuracy. Therefore, faced with the data provider's extensive and complex PDF documents spanning various types and industries, ComPDFKit encounters significant technical challenges.
Challenges in Tables
In PDF documents, recognizing and extracting data from tables presents a formidable challenge. Reports and literature across many industries often feature intricate tables with nested layers, merged cells, varying fonts, and border styles. These complexities in table structures make it particularly difficult to meet the demand for accurately extracting and formatting data.
For a typical table like the one above, the general table recognition effect is shown in the figure below, where extracted data lacks precision and is disrupted logical relationships. Using such data for AI analysis could lead to inaccurate results.

Challenges in Charts and Images
Most research reports, project documents, business plans, academic papers, and other documents in different industries contain various images and charts such as line graphs, bar charts, and pie charts. "Dirty data" in these charts, including legends, labels, axis values, titles, and footnotes, often impacts the effectiveness of AI model training.
Challenges in Module Distinction
PDF documents often contain diverse content like text, charts, and images, leading to irregular layouts. For instance, text may intertwine closely with charts, or images and tables may intersect in their arrangement. This diversity presents a significant challenge in accurately distinguishing modules. Traditional algorithms are often unable to effectively deal with such complex layout structures, resulting in disorganized content layouts.
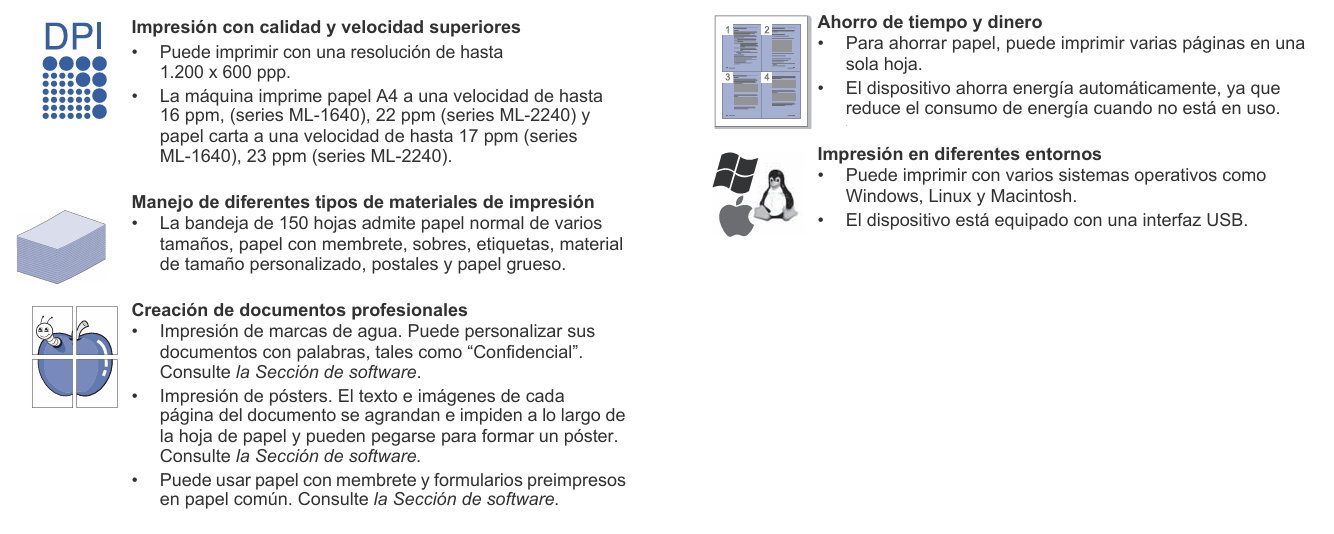
As shown in the picture below, traditional algorithms usually recognize the first line of text as "Impresión con calidad y velocidad superiores Ahorro de tiempo y dinero". This is due to the fact that traditional OCR algorithms recognize content line by line from left to right, without analyzing layout to differentiate modules. As a result, the extracted data lacks coherence and logic, which may lead to inaccurate results when AI conducts further analysis.
Challenges in Paragraph Processing
Paragraph processing is closely related to module distinction. After accurately analyzing and recognizing the layout of PDF documents, even though the structure of the document can be kept consistent with the original document, each module's text is still extracted line by line, treating each line as an independent paragraph. This data extraction method limits AI's ability to understand content, as it fails to capture logical relationships and semantic coherence between paragraphs. Effective paragraph processing requires more than simple text extraction; it should include accurate identification of paragraph boundaries and semantic analysis at the paragraph level to better understand and utilize information in the document.

Note: The left figure is recognized by traditional algorithms with line breaks in each line; the right figure is extracted by the ComPDFKit model, it is extracted by paragraph with only one line break in each paragraph.
What Is ComPDFKit's Solution
To address the complexity and accuracy challenges in PDF data extraction, ComPDFKit has specifically optimized processing for images, charts, tables, layouts, and paragraphs. Our R&D team customized an AI model specifically for efficiently parsing and extracting PDF document data based on the needs of this data provider. Building on this foundation, we tailored data detection parameters according to the client’s feedback, cleaning data that did not meet the criteria to ensure that the quality reached a high standard.
Through continuous optimization, we successfully processed over 3 million PDF documents within 5 days, achieving a data compliance rate of 88%, fully meeting client’s demands, and assisting in training more precise AI models.

Prospects for Future Cooperation
ComPDFKit has processed high-quality data and provided professional, timely technical support, attracting this data provider to pursue further collaboration with us. They plan to integrate ComPDFKit PDF SDK to independently extract data from PDF documents. In the future, they aim to integrate the ComIDP solution to handle other unstructured data, not limited to PDFs, expanding their business scope and offering more and higher-quality data to their clients.
If you are also facing the challenge of massive data processing, if you want to save labor costs, improve data quality, and enhance work efficiency, please visit our Intelligent Document Processing Solution page to learn about ComIDP's applications in AI training and enterprise system integration. We are dedicated to providing you with solutions to help you make the most of your data resources.