
Unlike Word documents, PDFs are designed to preserve visual layout rather than editable content, which makes text extraction more challenging. Fortunately, there are several effective methods to extract text from PDFs or scanned documents. In this article, we’ll explore five practical solutions—from basic copy-and-paste to using online tools, converters, and powerful SDKs or APIs for seamless integration into your own applications or systems.
With this guide, you'll be able to extract text from PDFs easily—for data analysis, content republishing, or feeding Large Language Models (LLMs).

Method 1: Copy and Paste Text from PDF
If you only need to extract a small amount of text, the simplest way is to select and copy it directly from your PDF. Most built-in PDF viewers on digital devices support this feature. If not, you can use advanced PDF editors like PDF Reader Pro to copy and paste text more effectively.
However, keep in mind that text in scanned PDFs or image-based PDFs can’t be copied directly—OCR (Optical Character Recognition) is required to extract text in these cases.
Method 2: Free Extract All Text from PDF Online
How to extract text from PDFs online? There are many web-based tools available for extracting text from PDFs. ComPDF offers two online demos that showcase the text extraction capabilities of our SDK. Both tools can extract all text from a PDF file efficiently, making them ideal for handling large volumes of content—no need for manual copy and paste.
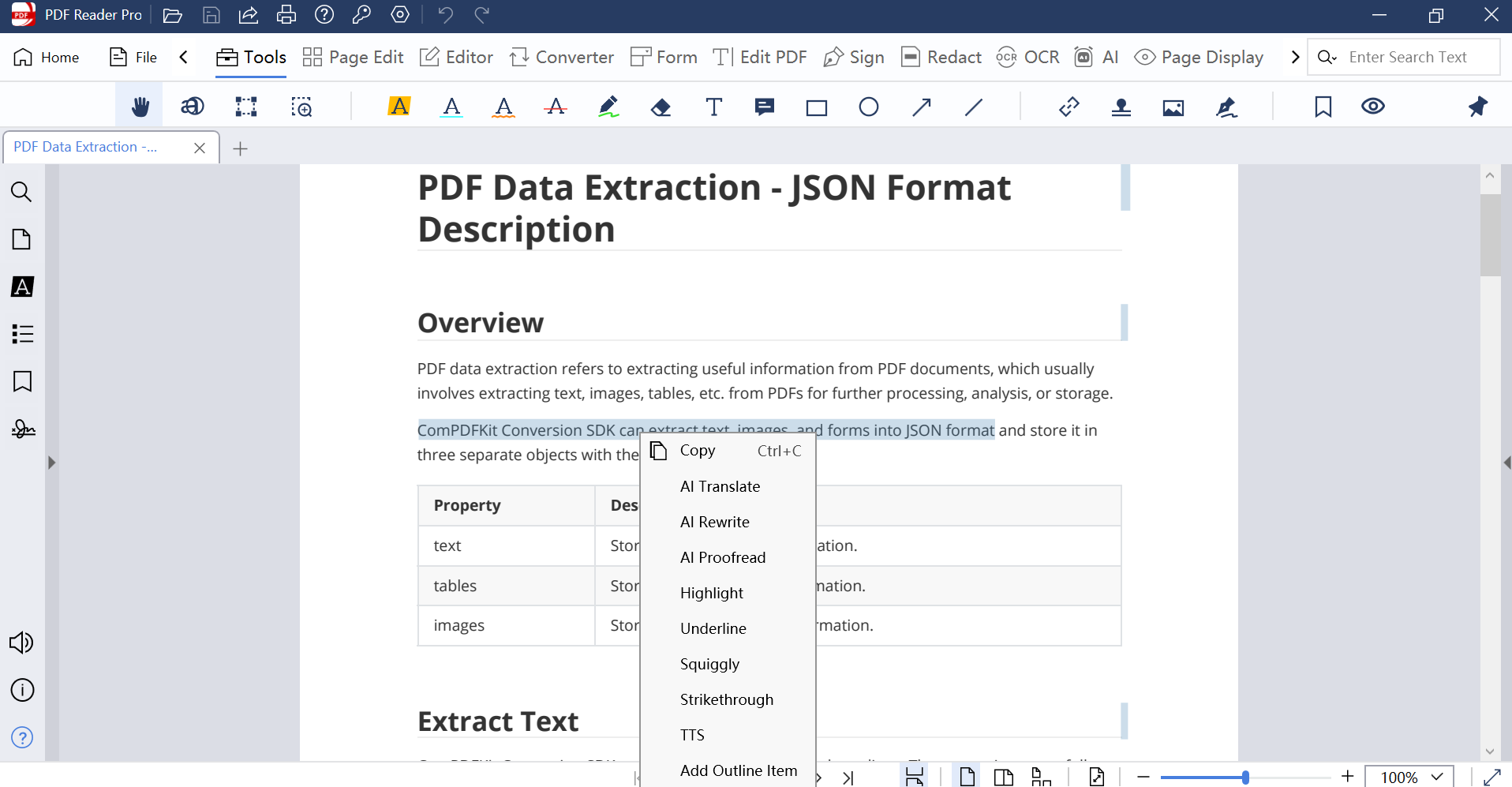
Free Online Tool: ComPDF Text Extraction Demo
Open API provides PDF data extraction tools on the official website, including extracting all content, text only, table only, or image only. To extract text from PDF documents, we recommend the Extract Text Only tool. Here’s how to do it.
Step 1: Go to the Extract Text Only demo page, and upload your PDF file.
Step 2: Select the format you want to preserve. Here we support TXT and JSON.
Step 3: If you need to extract text from an image or scanned PDF, make sure to enable the OCR option.
Step 4: If the uploaded file is encrypted, please enter the password.
Step 5: Click the Extract button and wait for the extracted TXT file to be auto-downloaded.
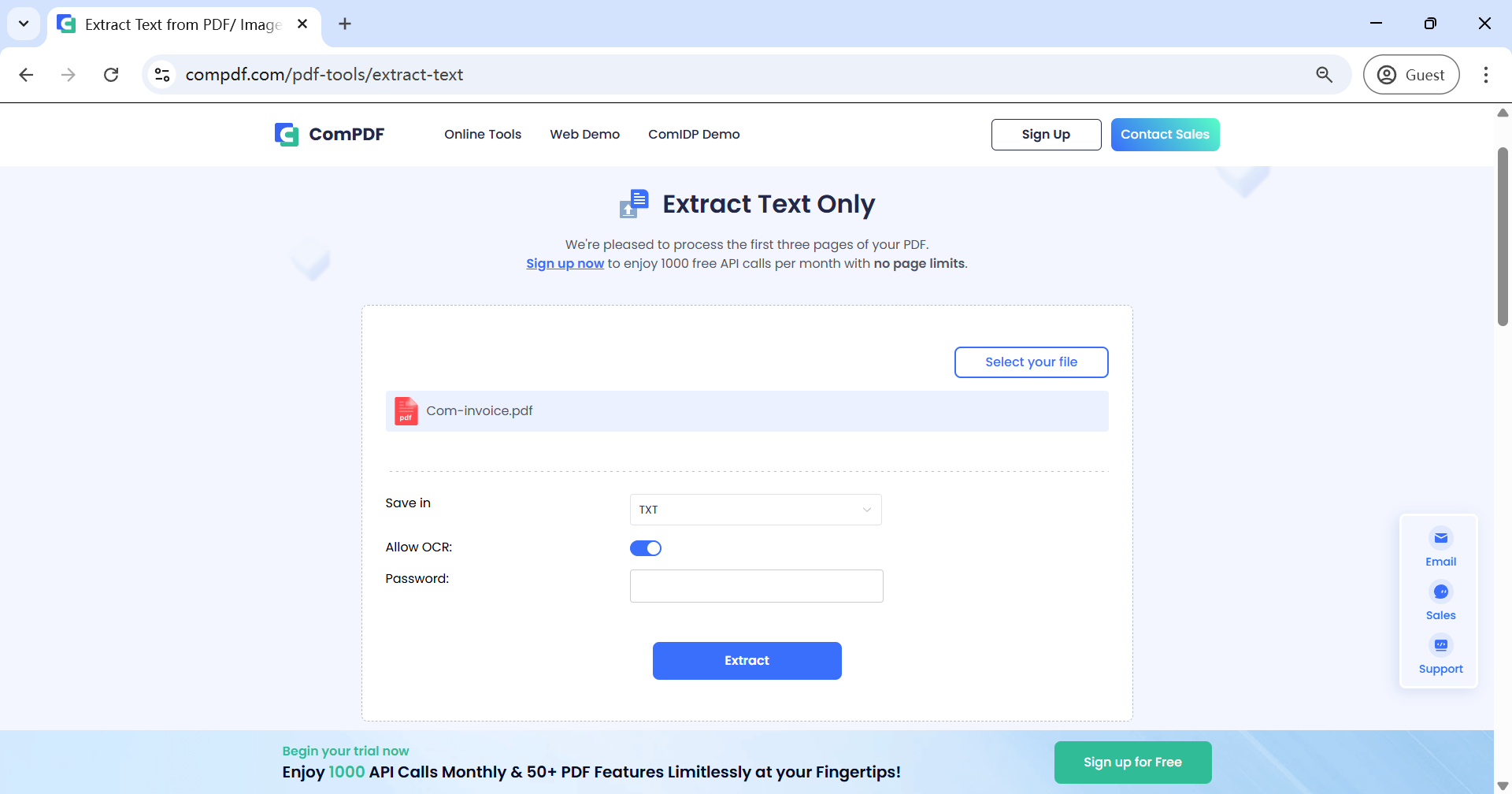
AI-based Online Tool: ComPDF AI(ComIDP) Text Extraction Demo
Sometimes, extracting text from complex PDFs using ComPDF's standard data extraction may not fully meet your needs. In such cases, it’s time to try ComPDF AI(ComIDP), which enables you to intelligently extract text from PDF documents. Powered by advanced AI technology, ComPDF AI(ComIDP) delivers more accurate and reliable results—especially for complex layouts or structured content.
Visit the ComPDF AI(ComIDP) Text Extraction demo, upload your file, and all text will be automatically extracted and displayed on the right side for you to copy and paste.
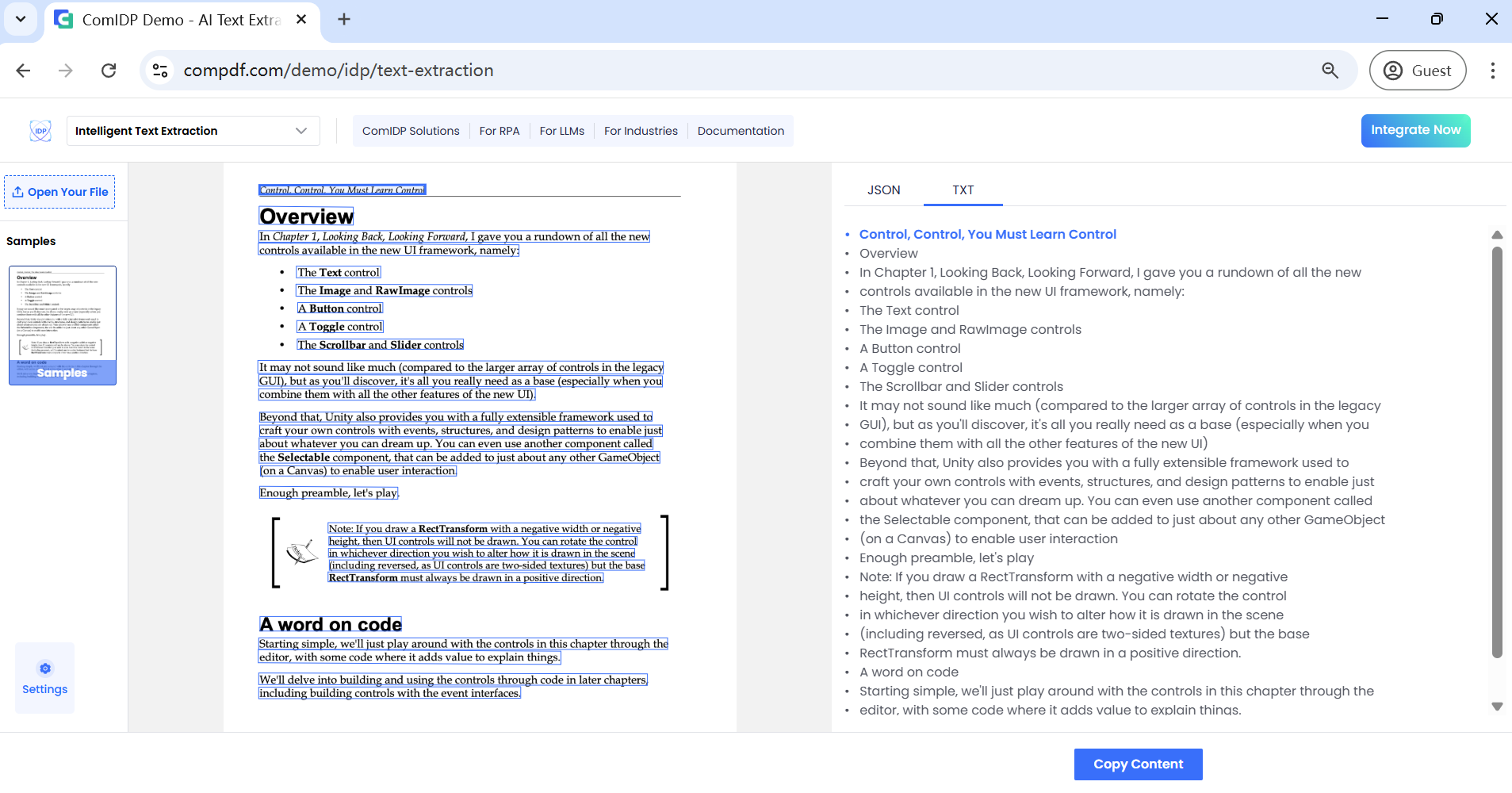
Method 3: Free Convert PDF to Readable Text Online
In fact, it is unnecessary to find a PDF text extraction tool; instead, a PDF to TXT converter is able to extract text from PDF. Open API also offers a free online conversion tool to convert PDF to readable text. Like the Extract Text Only demo, you can enable OCR to separate text from image-based or scanned PDFs.
Method 4: Integrate PDF Text Extraction into Your App
To embed the PDF text extraction feature into your apps, ComPDF offers both SDK and API for developers. It is compatible with various platforms, including Windows, Mac, Web, Android, iOS, and Server. Moreover, it provides multiple PDF conversion libraries such as C++, Java, Python, and PHP, ensuring versatility across different programming environments.
Follow the integration guide below to extract text from PDF with ComPDF Conversion SDK.
Step 1: Make a Program with ComPDF
Make sure you have met the system requirements and create a new Windows project in C#.
Step 2: Apply the License Key
Contact our sales team to obtain the necessary license for ComPDF Conversion SDK and apply it within your project. This step ensures proper authorization to utilize the SDK's functionality.
string resPath = "***";
string libPath = "***";
string license = "***";
CPDFConverter.InitLibrary(libPath);
CPDFConverter.InitResource(resPath);
CPDFConverter.LicenseVerify(license);
Step 3: Implement Text Extraction Code:
string inputFilePath = "***";
string outputFolderPath = "***";
string outputFileName = "***";
CPDFConverterJsonText converter = CPDFConvertFactroy.CreateConverter(CPDFConvertType.CPDFConvertTypeJsonText, inputFilePath) as CPDFConverterJsonText;
CPDFConvertJsonOptions jsonOptions = new CPDFConvertJsonOptions();
jsonOptions.IsAllowOCR = false;
ConvertError error = ConvertError.ERR_UNKNOWN;
jsonTextConverter.Convert(outputFolderPath, ref outputFileName, jsonOptions, ref error);
If you want to extract PDF text more intelligently, it is recommended integrating ComPDF AI(ComIDP) into your system following the Intelligent Text Extraxtion API guide.
Method 5: Convert PDF to Text with Open API
In addition to the PDF Text Extraction SDK, Open API offers a convenient PDF to TXT interface that allows you to extract all text from PDF documents.
The processing workflow of the Open API is very simple. It consists of four basic request instructions: create a task, upload a file, execute a task, and download a result file. Below is a quick example using the Java library to convert PDF to TXT.
Step 1: Register the Open API account to get 1000 free calls per month.
Step 2: Get the API Keys on the account dashboard and authenticate your project.
Step 3: Create a task, upload a file, execute the converting PDF to TXT task, and get the result file.
// Create a client
CPDFClient client = new CPDFClient(publicKey,secretKey);
// Create a task
// Create an example of a PDF tO TXT task
CPDFCreateTaskResult result = client.createTask(CPDFConversionEnum.PDF_TO_TXT);
// Get a task id
String taskId = result.getTaskId();
// Upload files
client.uploadFile(new File("test.pdf"), taskId);
// Execute task
client.executeTask(taskId);
// Query TaskInfo
CPDFTaskInfoResult taskInfo = client.getTaskInfo(taskId);
If you prefer using the ComPDF Conversion SDK for local integration, please refer to the PDF to TXT guide for detailed instructions.
FAQs about PDF Text Extraction
Q1: What makes PDF text extraction tricky?
A: PDFs are designed to preserve layout, not structure. Text therein may be stored in fragmented blocks, unusual orders, or as images. This lack of standard formatting makes it hard to extract clean, structured text—especially from scanned or complex documents.
See also: What's So Hard about PDF Text Extraction?– Reasons and Solutions
Q2: How to extract text from a scanned PDF?
A: To extract text from a scanned PDF, you need OCR (Optical Character Recognition) technology. Tools like ComPDF AI(ComIDP) or ComPDF can recognize and extract text within image-based PDFs into selectable, editable content.
Q3: What is the best way to extract text from PDF docs for fine-tuning models?
A: Use AI-powered tools like ComPDF AI(ComIDP) for accurate, structured text extraction. They handle complex layouts and unstructured data better than traditional extractors—ensuring cleaner inputs for fine-tuning models like LLMs.
Q4: Should I choose ComPDF Conversion SDK or ComPDF AI(ComIDP)?
A: Choose the ComPDF Conversion SDK for simple, rule-based PDF to text tasks. Go with ComPDF AI(ComIDP) if you need intelligent, AI-driven extraction—ideal for complex layouts, scanned documents, or structured data needs.
Final Words
How to extract text from PDFs? In this article, we covered three user-friendly methods for extracting text from PDFs, along with two developer-focused solutions for integrating text extraction into your apps or systems using the ComPDF Conversion SDK or API.
If you are interested in AI-powered PDF text extraction solution, explore our ComPDF AI(ComIDP) solution now!